Como integrar n8n com Ollama para criar workflows de LLM locais
Jan 08, 2026
/
Bruno S.
/
12 min de leitura
A integração entre n8n e Ollama permite usar diferentes modelos de IA diretamente nos seus workflows de automação. Isso abre espaço para executar tarefas mais complexas, que seriam difíceis ou inviáveis sem o uso de LLMs rodando localmente.
Apesar disso, o processo exige atenção, já que é preciso configurar corretamente os dois lados para que tudo funcione sem erros. A boa notícia é que, se você já tem o n8n e o Ollama instalados no servidor, a integração pode ser feita em poucos passos.
De forma geral, o processo envolve:
- Adicionar o node de chat do Ollama
- Escolher o modelo de IA e ajustar as configurações de execução
- Configurar o prompt no node de AI agent
- Enviar um prompt de teste para validar se tudo está funcionando
Depois disso, você terá um workflow de processamento com IA usando n8n Ollama, pronto para ser integrado a automações mais completas. Por exemplo, dá para conectar aplicativos de mensagens, como o WhatsApp, e criar um chatbot funcional baseado em IA.
Outro ponto importante é que rodar essa integração localmente, em um servidor privado como um VPS, oferece mais controle sobre os dados. Isso torna o uso ideal para automações que lidam com informações sensíveis, como resumir documentos internos ou criar um chatbot interno para a empresa.
A seguir, vamos ver em detalhes como conectar o Ollama ao n8n e montar um chatbot com essa integração. No final, também explicamos os casos de uso mais comuns e como expandir as possibilidades usando os nodes do LangChain.
Pré-requisitos
Para integrar o n8n com o Ollama, você precisa atender aos seguintes pré-requisitos:
- O Ollama deve ser instalado localmente. Certifique-se de ter instalado o Ollama localmente em um servidor virtual privado (VPS). O servidor deve ter hardware suficiente para executar os modelos de IA desejados, o que pode exigir mais de 8 GB de RAM.
- O n8n deve estar configurado e acessível. Instale o n8n em um VPS e crie uma conta. Ele deve ser configurado no mesmo servidor que o Ollama devido a restrições de compatibilidade.
- Certifique-se de que as portas necessárias estejam abertas. Verifique se as portas 11434 e 5678 do seu servidor estão abertas para garantir que o Ollama e o n8n estejam acessíveis. Se você os hospeda em um VPS da Hostinger, verifique as portas e configure-as simplesmente consultando nosso assistente de IA Kodee.
- Conhecimento básico de JSON. Aprenda a ler JSON, pois os nós n8n trocam dados principalmente nesse formato. Compreendê-lo ajuda você a selecionar dados e solucionar erros com mais eficiência.
Importante! Recomendamos fortemente a instalação do n8n e do Ollama no mesmo contêiner Docker para melhor isolamento. Este é o método que usamos para testar este tutorial, portanto, está comprovado que funciona.
Se você usa um VPS da Hostinger, pode começar instalando o n8n ou o Ollama em um contêiner Docker, bastando selecionar o modelo de sistema operacional correspondente – o aplicativo será instalado em um contêiner por padrão. Em seguida, você precisará instalar o outro aplicativo no mesmo contêiner.
Como configurar a integração do Ollama no n8n
Conectar o Ollama ao n8n envolve adicionar o node necessário e ajustar algumas configurações para que os dois funcionem juntos. Nesta seção, vamos explicar o passo a passo em detalhes, incluindo como testar se a integração n8n Ollama está funcionando corretamente.
1. Adicione o node Ollama Chat Model
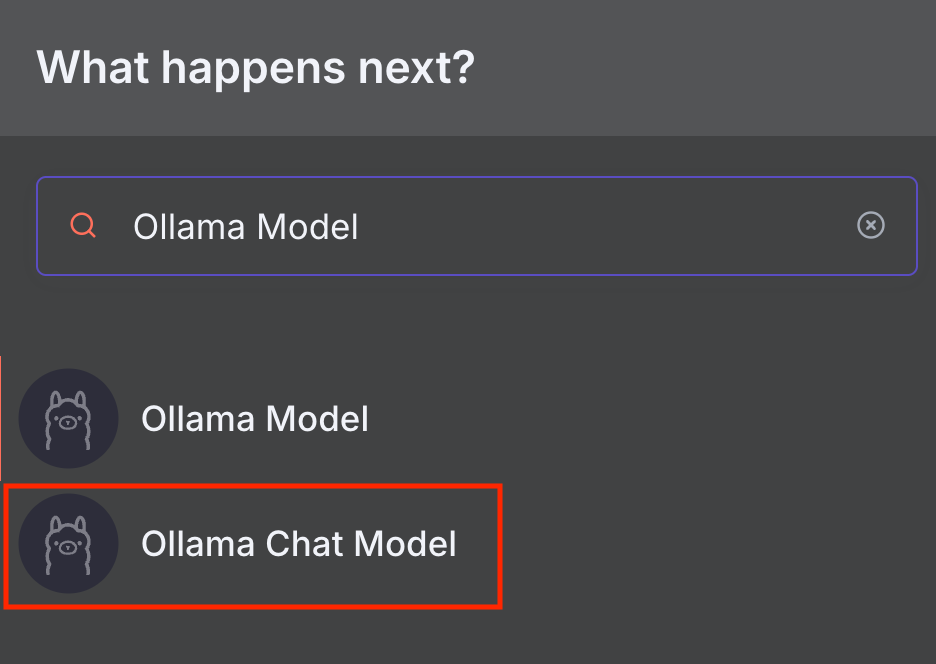
Adicionar o node Ollama Chat Model permite que o n8n se conecte a modelos de linguagem (LLMs) do Ollama por meio de um agente conversacional.
O n8n oferece dois nodes relacionados ao Ollama: Ollama Model e Ollama Chat Model. O Ollama Chat Model foi pensado especificamente para conversas e já vem com um node Basic LLM Chain integrado, que encaminha sua mensagem para o modelo escolhido. Já o node Ollama Model é mais indicado para tarefas gerais, combinado com outros nodes de Chain – falaremos melhor sobre isso na seção de LangChain.
Neste tutorial, vamos usar o Ollama Chat Model porque ele é mais simples de configurar e encaixa melhor em um workflow mais completo. Veja como adicionar no n8n:
- Acesse a sua instância do n8n. Em geral, você consegue abrir no navegador usando o hostname ou o endereço IP do seu VPS, dependendo de como você configurou.
- Faça login na sua conta n8n.
- Crie um novo workflow clicando no botão no canto superior direito da página inicial do n8n.
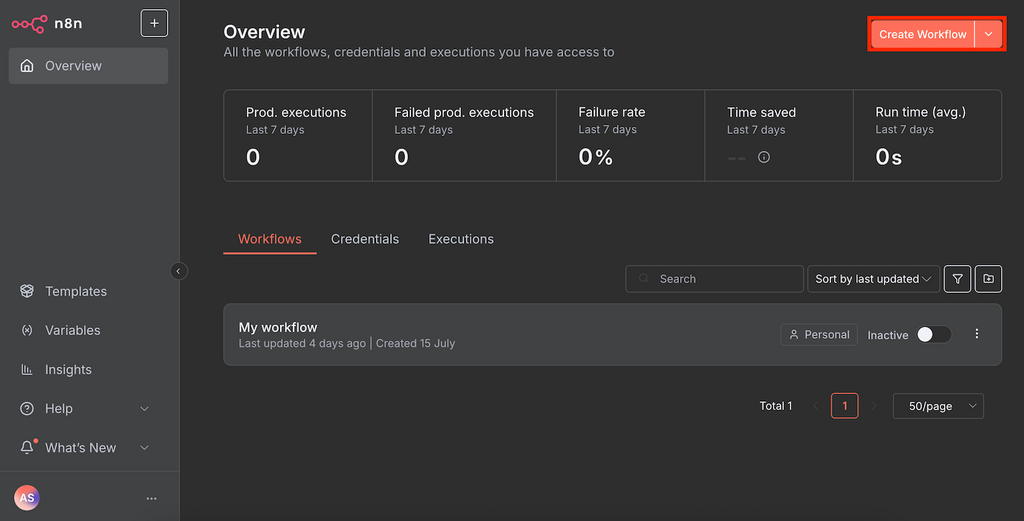
- Clique no ícone de mais e pesquise por Ollama Chat Model.
- Adicione o node clicando nele.
A janela de configuração do node vai aparecer. No próximo passo, vamos ajustar as configurações para deixar a integração n8n Ollama pronta para uso.
2. Escolha o modelo e configure as opções de execução
Antes de selecionar um modelo de IA e ajustar as configurações de execução, é preciso conectar o n8n à sua instância do Ollama hospedada localmente. Veja como fazer isso:
- Na janela de configuração do nó, expanda o menu suspenso “Credenciais para conectar”.
- Selecione Criar nova credencial.
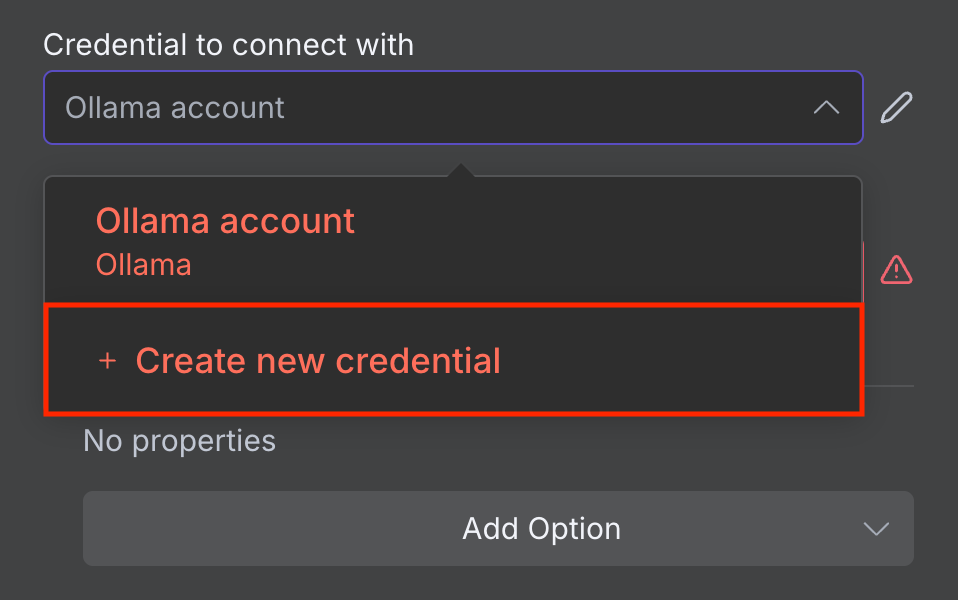
- Insira a URL base da sua instância do Ollama. Dependendo do seu ambiente de hospedagem, pode ser localhost. ou o nome do seu contêiner Docker do Ollama.
- Clique em Salvar.
Se a conexão der certo, você verá uma mensagem de confirmação. Caso contrário, confira se o endereço está correto e se o Ollama está em execução.
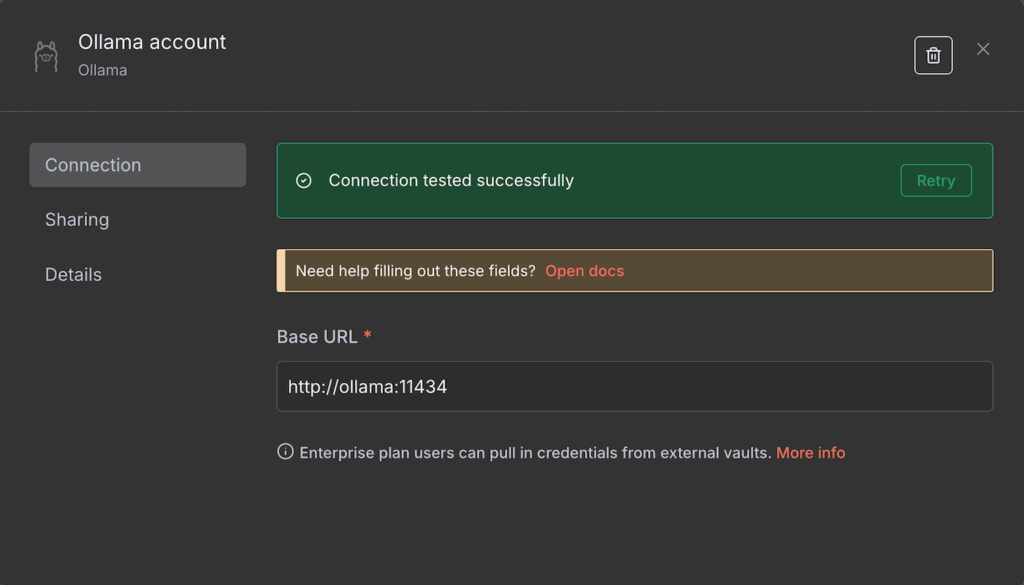
Depois de conectar, você já pode escolher qual LLM usar no node do Ollama. Para isso, basta abrir o menu Model e selecionar um modelo da lista. Se a lista aparecer desativada (acinzentada), atualizar a página do n8n costuma resolver.
Vale notar que, no momento, o n8n oferece suporte apenas a modelos mais antigos, como Llama 3 e DeepSeek R1. Se o menu Model mostrar erro ou aparecer vazio, provavelmente o seu Ollama só tem modelos incompatíveis instalados.
Para resolver isso, basta baixar outros modelos no Ollama. Pelo terminal (CLI), use o comando abaixo no ambiente onde o Ollama está rodando:
ollama run nome-do-modelo
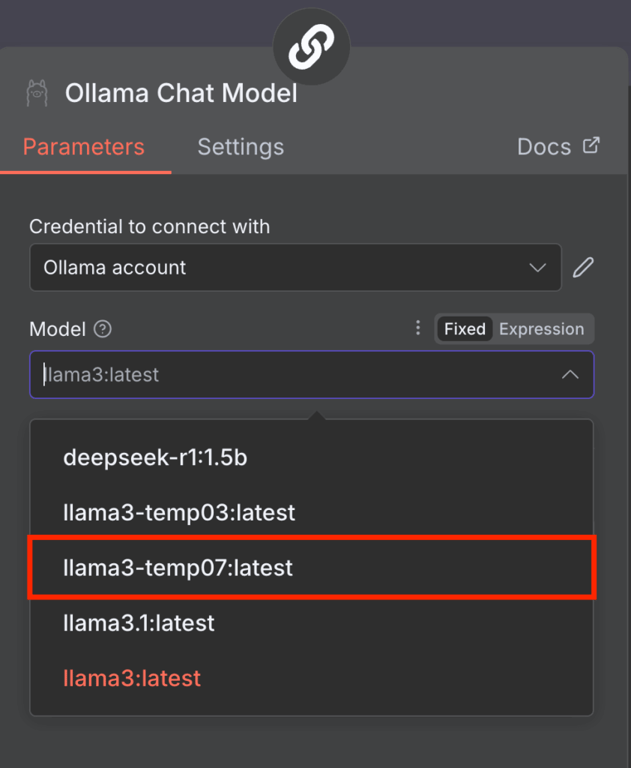
Você também pode usar um modelo com configurações de execução personalizadas, como uma temperatura diferente. Veja como criar isso usando o Ollama CLI.
- Primeiro, acesse a instalação do Ollama. Se estiver usando Docker, rode o comando abaixo (substituindo ollama pelo nome real do container):
docker exec -it ollama bash
- Crie um novo arquivo Modelfile definindo as configurações de tempo de execução do seu modelo. Por exemplo, vamos definir a temperatura do nosso modelo Llama 3 para 0,7,:
echo "FROM llama3" > Modelfile echo "PARAMETER temperature 0.7" >> Modelfile
- Depois, aplique essa configuração ao modelo base Llama 3 para criar um LLM personalizado chamado llama3-temp07:
ollama create llama3-temp07 -f Modelfile
Ao concluir esses passos, o n8n já deve reconhecer o novo modelo Llama 3 com temperatura personalizada em 0.7.
Gerenciando modelos pelo Ollama GUI
Se você usa Ollama GUI, confira nosso tutorial para aprender mais sobre sua interface e como gerenciar seus modelos.
3. Configure as opções de prompt
Configurar os prompts permite personalizar como o node Basic LLM Chain trata sua entrada antes de enviá-la ao Ollama para processamento. Embora seja possível usar as configurações padrão, o ideal é ajustá-las de acordo com o tipo de tarefa que você quer executar no workflow n8n Ollama.
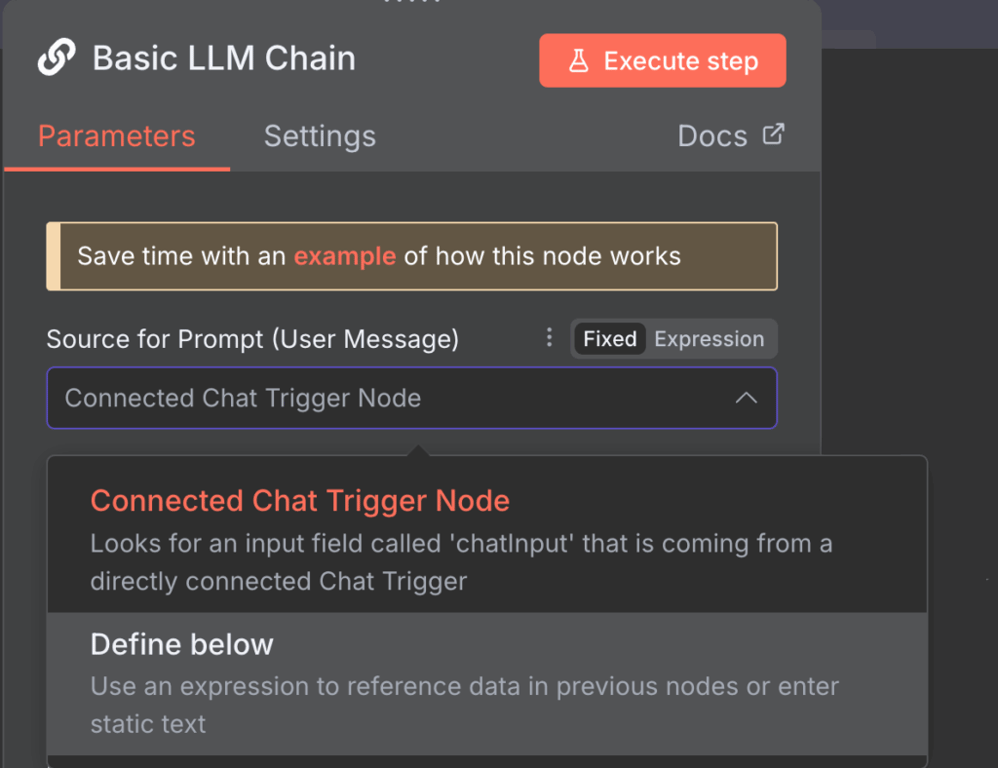
Existem duas formas principais de modificar as configurações de prompt do LLM chain, cada uma indicada para um tipo de uso.
Chat Trigger conectado
A opção Connected Chat trigger node usa as mensagens do node Chat padrão como entrada para o Ollama. Esse é o modo ativado por padrão e envia as mensagens exatamente como foram recebidas.
Mesmo assim, você pode adicionar prompts extras para influenciar a resposta do modelo. Para isso, clique em Add Prompt na opção Chat Messages (if Using a Chat Model) e escolha entre três tipos de prompt adicionais:
- IA. Insira um exemplo da resposta esperada no campo Mensagem. O modelo de IA tentará responder da mesma forma que o texto fornecido.
- Sistema. Escreva uma mensagem que oriente as respostas do modelo. Por exemplo, você pode definir o tom que a IA usará ou as palavras que ela deve evitar ao responder.
- Usuário. Adicione um exemplo da entrada do usuário para a IA, como uma mensagem, URL ou imagem. Fornecer à IA uma amostra do que esperar dos usuários permitirá que ela retorne respostas mais consistentes.
Define below
A opção “Define below” é adequada se você quiser inserir um texto predefinido e reutilizável. É também ideal para encaminhar dados dinâmicos, pois permite capturá-los usando Expressões – uma biblioteca JavaScript que manipula a entrada ou seleciona um campo específico.
Por exemplo, o node anterior coleta dados sobre o uso de recursos do seu VPS e você deseja analisá-los usando IA. Nesse caso, o aviso permanece o mesmo, mas as métricas de uso mudarão continuamente.
Seu prompt pode ser semelhante ao seguinte, onde {{ $json.metric }} é o campo que contém dados dinâmicos sobre o uso de recursos do seu servidor:
O uso mais recente do meu servidor é {{ $json.metric }}. Analise esses dados e compare com o histórico anterior para verificar se há algo fora do padrão.Vale lembrar que você ainda pode adicionar prompts extras, como no modo anterior, para dar mais contexto ao modelo de IA.
4. Envie um prompt de teste
Enviar um prompt de teste serve para confirmar se o modelo do Ollama está funcionando corretamente ao receber entradas via n8n. A forma mais simples de fazer isso é enviar uma mensagem de exemplo seguindo estes passos:
- Salve o workflow clicando no botão no canto superior direito do canvas.
- Passe o mouse sobre o node Chat trigger e clique em Open chat.
- Na interface de chat, envie uma mensagem de teste.
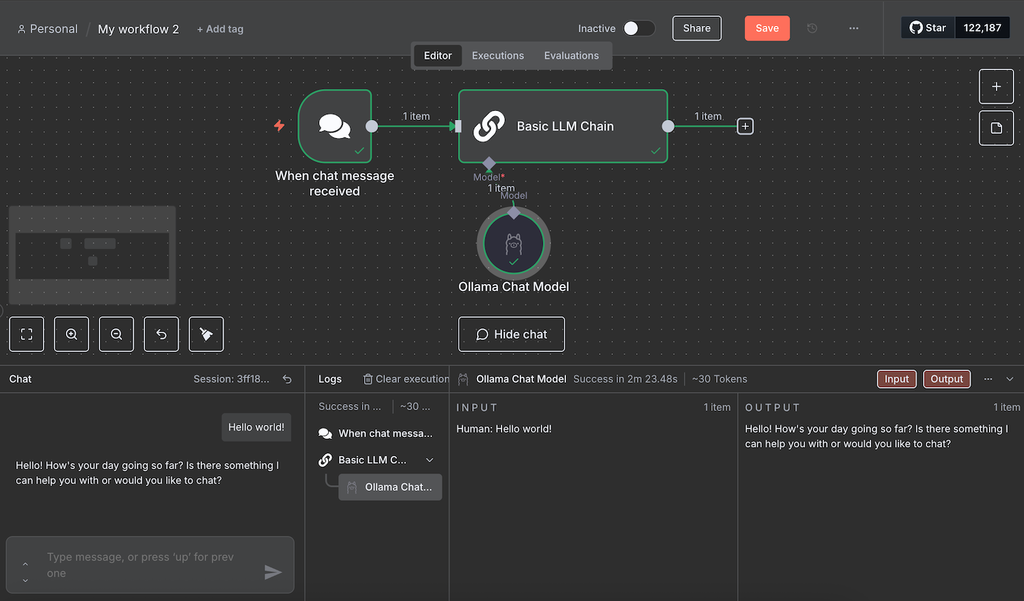
Aguarde até o workflow terminar de processar a mensagem. Durante nossos testes, o fluxo travou algumas vezes. Se isso acontecer com você, basta recarregar o n8n e enviar a mensagem novamente.
Se o teste for bem-sucedido, todos os nodes ficarão verdes. Para ver os dados de entrada e saída de cada node, dê um duplo clique nele e confira os painéis dos dois lados da janela de configuração.
Como criar um workflow de chatbot usando Ollama e n8n
Integrar o Ollama ao n8n permite automatizar várias tarefas com LLMs, incluindo a criação de um workflow com IA no n8n capaz de responder a perguntas dos usuários, como um chatbot. Nesta seção, vamos mostrar os passos para desenvolver esse tipo de automação usando n8n Ollama.
Se você deseja criar um sistema de automação para outras tarefas, confira nossos exemplos de fluxo de trabalho n8n para se inspirar.
1. Adicione um node de gatilho (trigger)
O node de gatilho no n8n define qual evento inicia o workflow. Para criar um chatbot, estas são as opções mais comuns.
Chat trigger
Por padrão, o node Ollama Chat Model usa Chat message como gatilho, iniciando o workflow sempre que uma mensagem é recebida.
Esse Chat node padrão é ideal para criar um chatbot. Para colocá-lo em funcionamento, basta tornar a interface de chat pública.
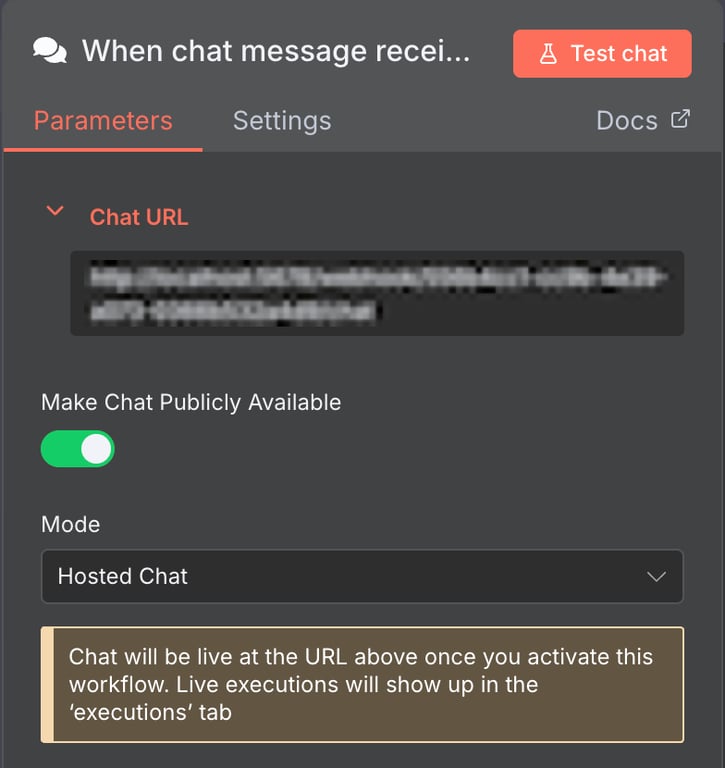
Depois disso, você pode incorporar esse chat em um chatbot próprio, com interface personalizada.
Nodes de gatilho para apps de mensagens
O n8n também oferece nodes de gatilho para aplicativos populares de mensagens, como Telegram e WhatsApp. Eles são indicados se você quiser criar um bot para essas plataformas.
A configuração costuma ser mais complexa, já que exige conta de desenvolvedor e chaves de autenticação para acessar as APIs. Consulte a documentação de cada serviço para entender o processo em detalhes.
Webhook trigger
O gatilho Webhook inicia o workflow quando a URL do endpoint recebe uma requisição HTTP. Essa opção é útil se você quiser disparar o chatbot a partir de outros eventos, como um clique em um botão.
Nos próximos passos, vamos usar esse node para iniciar o workflow sempre que um chatbot do Discord receber uma mensagem.
Importante! Se o URL do seu webhook começar com localhost, altere-o para o domínio, nome do host ou endereço IP do seu VPS. Você pode fazer isso modificando a variável de ambiente WEBHOOK_URL do n8n dentro do seu arquivo de configuração.
2. Conecte o node do Ollama
Conectar o node do Ollama permite que o node de gatilho envie a entrada do usuário para processamento com IA.
O node Ollama Chat Model não se conecta diretamente aos gatilhos. Ele precisa ser ligado a um node de IA. O padrão é o Basic LLM Chain, mas você também pode usar outros Chain nodes se precisar de um processamento mais avançado.
Alguns Chain nodes oferecem ferramentas extras para tratar os dados. Por exemplo, o node AI Agent permite adicionar um parser para reformatar a resposta ou usar memória para armazenar mensagens anteriores.
Para um chatbot simples, que não exige processamento complexo – como o chatbot de Discord deste exemplo – o Basic LLM Chain é suficiente.
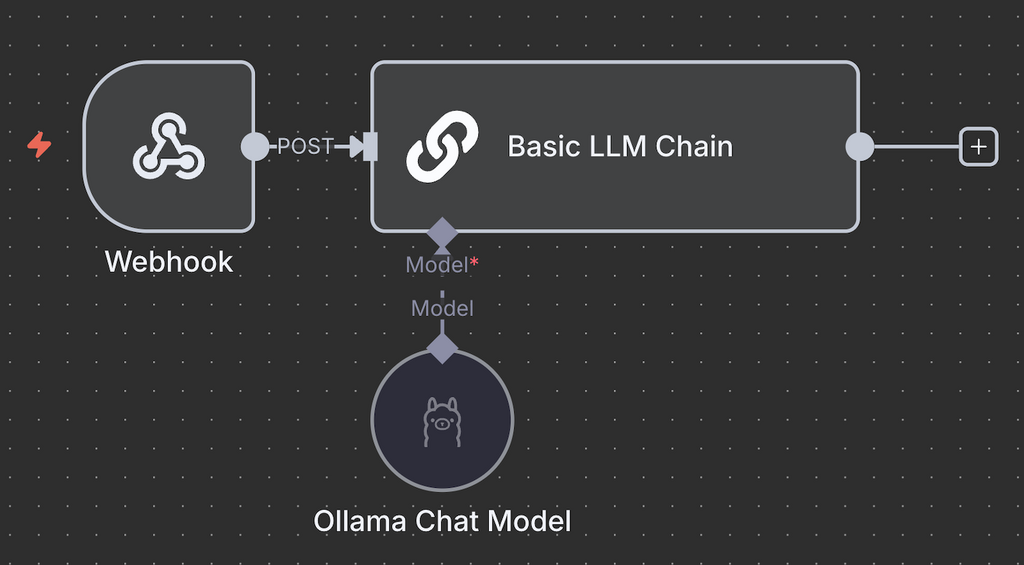
Agora, conecte o node de gatilho ao Basic LLM Chain e defina como a entrada será enviada. Use a opção Fixed para passar a mensagem diretamente como prompt. Já a opção Expression é ideal quando você precisa trabalhar com dados dinâmicos ou ajustar a entrada antes de enviá-la ao Ollama.
Por exemplo, neste caso usamos a expressão abaixo para selecionar o campo JSON body.content como entrada, que muda de acordo com a mensagem enviada no Discord:
{{ $json.body.content }}3. Exiba a resposta do chatbot
Para que os usuários vejam a resposta gerada pelo modelo, é preciso enviar a saída do node AI Agent ou do Basic LLM Chain para algum canal de retorno. Nesse ponto, a resposta pode ser visualizada apenas pela interface de chat do n8n ou pelo painel de saída do node.
Para enviar a mensagem ao usuário, use um node compatível com o gatilho escolhido. Por exemplo, ao criar um chatbot no WhatsApp, conecte o node WhatsApp send message.
Se você estiver usando o Chat trigger padrão, também pode usar um Webhook para encaminhar a resposta para um bot ou interface de chatbot desenvolvida por você.
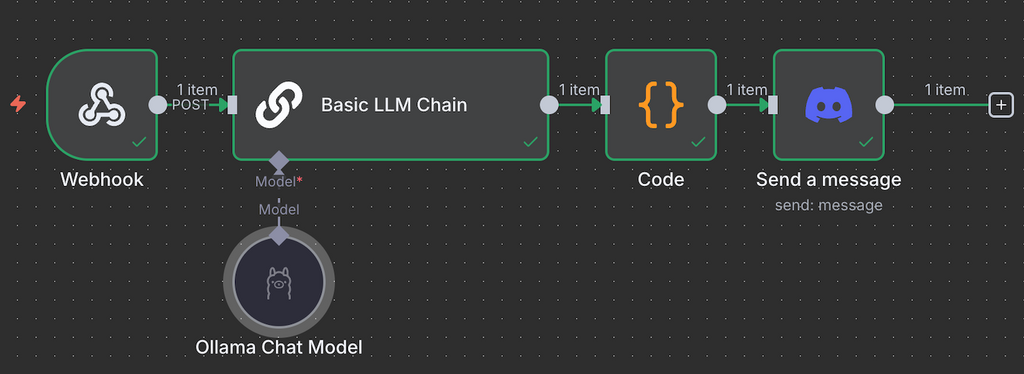
No caso do nosso chatbot de Discord, como o workflow usa um Webhook trigger, podemos usar o próprio Webhook para retornar a resposta. Outra opção é enviar a mensagem diretamente pelo bot, conectando o node Discord Send a Message e integrando-o ao chatbot. O workflow final fica mais ou menos assim:
Não sabe como criar um fluxo de trabalho completo?
O n8n oferece vários fluxos de trabalho prontos para uso que você pode importar facilmente para sua tela. Isso permite criar um sistema de automação baseado em IA sem precisar desenvolver o fluxo de trabalho do zero. Confira nosso tutorial com os melhores modelos n8n para descobrir fluxos de trabalho selecionados e prontos para uso para diversas finalidades.
Quais são os melhores casos de uso para a integração n8n-Ollama?
Como uma das ferramentas mais poderosas de automação com IA, a integração do n8n com os LLMs personalizáveis do Ollama permite automatizar uma grande variedade de tarefas.
Aqui estão alguns exemplos de tarefas que você pode automatizar com o n8n e IA:
- Fluxo de trabalho automatizado de suporte ao cliente. Use os LLMs da Ollama para gerar respostas a consultas de clientes, resumir tickets ou encaminhar problemas em plataformas como Zendesk e Intercom, tudo via n8n.
- Redação de e-mails contextualizados. Redija e-mails automaticamente para diferentes contextos ou tarefas usando o Ollama. Por exemplo, você pode escrever uma mensagem para dar as boas-vindas a um novo cliente potencial, lembrar os clientes sobre o vencimento da assinatura e anunciar atualizações de produtos usando diferentes eventos.
- Assistente interno da base de conhecimento. Use o n8n para consultar documentação interna, como Notion, Confluence ou Airtable, e alimente o Ollama com os dados para gerar respostas inteligentes ou resumos para consultas internas da equipe.
- Extração e sumarização de dados. Use o n8n para monitorar documentos de texto recebidos, extrair o texto e obter informações importantes com o Ollama – útil para resumir relatórios, faturas ou documentos jurídicos.
- Fluxo de produção de conteúdo automatizado. Gere conteúdo usando n8n e Ollama criando um fluxo de trabalho que automatiza a pesquisa de palavras-chave, a redação e o processo de edição.
- Chatbots seguros para uso interno. Crie chatbots internos que trabalhem com dados internos sensíveis, onde o n8n cuida da orquestração e o Ollama executa o LLM completamente offline para segurança e privacidade.
Por que você deve hospedar seus fluxos de trabalho n8n-Ollama com a Hostinger?
Hospedar seus fluxos de trabalho n8n-Ollama com a Hostinger traz diversas vantagens em relação ao uso de uma máquina pessoal ou do plano de hospedagem oficial. Aqui estão alguns dos benefícios:
- Maior controle. O serviço de hospedagem VPS n8n da Hostinger oferece aos usuários acesso root completo às configurações e aos dados do servidor. Isso permite que você configure seus ambientes de hospedagem n8n e Ollama de acordo com suas preferências específicas.
- Privacidade aprimorada. Como você hospedará o n8n e o Ollama em um servidor sobre o qual terá controle total, terá a liberdade de ajustar os limites de acesso e as configurações de segurança.
- Escalabilidade. Os planos VPS da Hostinger são facilmente atualizáveis sem tempo de inatividade e oferecem o modelo de modo de fila n8n, que permite delegar suas tarefas a vários servidores.
- Configuração simplificada. Nossos modelos de VPS permitem que você instale o n8n ou o Ollama com um único clique, tornando o processo mais eficiente.
- Gestão fácil. Gerenciar um VPS da Hostinger é fácil com o painel de controle intuitivo hPanel ou com o terminal integrado do navegador. Usuários iniciantes também podem solicitar que nosso assistente de IA, Kodee, execute tarefas de administração do sistema via chat.
Usando o node LangChain LM Ollama no n8n
O LangChain é um framework que facilita a integração de modelos de linguagem (LLMs) em aplicações. No n8n, isso acontece conectando nodes de ferramentas e modelos de IA para alcançar capacidades específicas de processamento.
No n8n, o recurso de LangChain funciona com Cluster nodes – um conjunto de nodes interligados que trabalham juntos para entregar uma funcionalidade dentro do workflow.
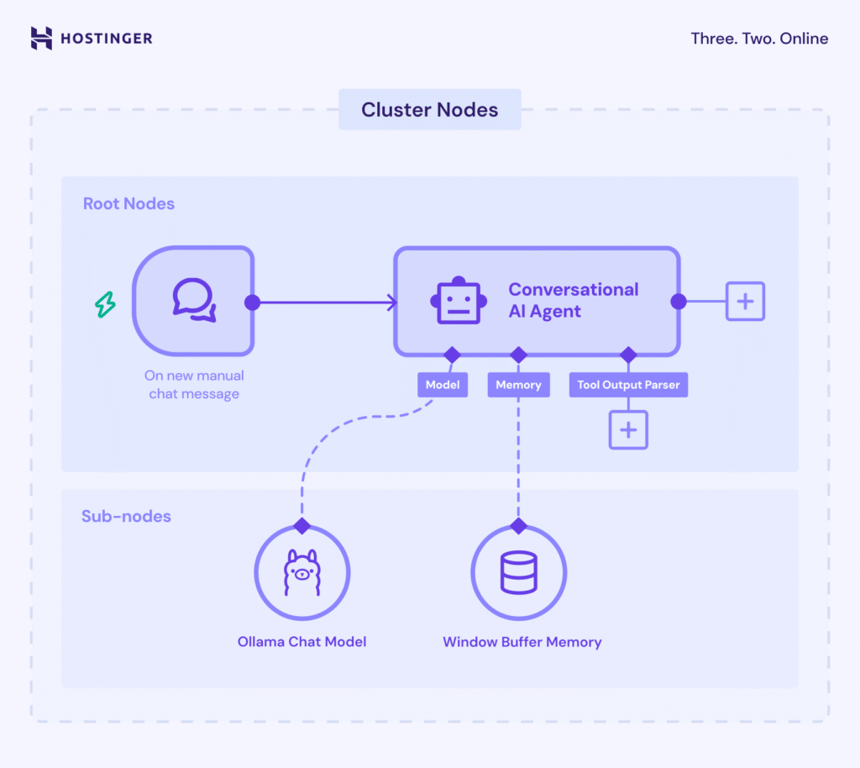
Os Cluster nodes têm duas partes: os root nodes, que definem a funcionalidade principal, e os sub-nodes, que adicionam a capacidade de LLM ou recursos extras.
O ponto mais importante da implementação do LangChain no n8n é a Chain dentro dos root nodes. É ela que organiza a lógica e conecta os diferentes componentes de IA – como o modelo do Ollama e um node de parser – para formar um sistema coeso.
Estas são as Chains disponíveis no n8n e o que cada uma faz:
- Basic LLM Chain. Permite definir o prompt que o modelo vai usar e, se quiser, adicionar um parser para reformatar a resposta.
- Retrieval Q&A Chain. Permite recuperar informações processadas pela IA usando vector stores, que são bancos otimizados para armazenar dados em formato numérico (vetores).
- Summarization Chain. Resume o conteúdo de vários documentos ou entradas.
- Sentiment Analysis. Analisa o sentimento do texto de entrada e classifica em categorias como positivo, neutro e negativo.
- Text Classifier. Organiza os dados de entrada em categorias criadas por você, com base em critérios e parâmetros definidos no workflow.
Ao criar um workflow no n8n, você também pode encontrar os Agents – que são variações de Chains com capacidade de “tomar decisões”. Enquanto as Chains seguem regras pré-definidas, um Agent usa o LLM conectado para decidir quais serão os próximos passos e quais ações executar.
O que vem a seguir depois de conectar o n8n com o Ollama?
Com a evolução contínua das tendências de automação, a implementação de um sistema automático de processamento de dados ajudará você a se manter à frente da concorrência. Em conjunto com a IA, você pode criar um sistema que levará o desenvolvimento e a gestão de seus projetos a um novo patamar.
A integração do Ollama ao seu fluxo de trabalho n8n leva a automação baseada em IA além das capacidades do nó integrado – e a compatibilidade do Ollama com vários LLMs permite que você escolha e personalize diferentes modelos de IA para melhor atender às suas necessidades.
Entender como integrar o Ollama ao n8n é apenas o primeiro passo para implementar a automação com inteligência artificial em seu projeto. Considerando a enorme quantidade de casos de uso possíveis, o próximo passo é experimentar e desenvolver um fluxo de trabalho que melhor se adapte ao seu projeto.
Se for a sua primeira vez a trabalhar com n8n ou Ollama, a Hostinger é o local ideal para começar.
Semua konten tutorial di website ini telah melalui peninjauan menyeluruh sesuai padrões editoriais e valores da Hostinger.

Bruno é redator de conteúdo na Hostinger, focado em criar e otimizar artigos úteis e envolventes sobre desenvolvimento web e marketing. Com formação em jornalismo, ele combina storytelling com insights práticos para tornar temas complexos mais fáceis de entender. Também já colaborou com publicações como MacMagazine e Jornal A Tarde. Fora do trabalho, gosta de respirar arte, cozinhar e acompanhar novidades no mundo da tecnologia.